Research Interest
My primary areas of interest in research are computer vision and machine learning .
Most of our understanding of the world stems from interpreting complex sensory signals, particularly visual information, yet turning this raw data into meaningful knowledge remains a fundamental challenge in artificial intelligence.
My research aims to develop visual intelligence that can perceive, process and reason about visual signals with generality and scalability.
Lab Openings
I seek highly motivated candidates with strong technical backgrounds in AI/ML who share our passion for advancing visual intelligence, particularly through the following three directions:
Generative Understanding : Constructing and learning from generative models of the world. Multimodal Learning : Connecting visual representations to commonsense knowledge base like LLMs to achieve higher-order cognition.Self-Supervised Learning : Discovering structures in raw data to obtain scalable structured representations in wide domains of images and videos , and applicable to a variety of tasks .2025 Fall PhD Applicants: Please submit your application to the Rice CS PhD program , due Jan. 1, 2025 with no application fee, and mention me as one of your Faculty of Interest.
While I will review all relevant applications, contacting me after submission through email can help flag your application.
Rice Students : If you are a Rice student looking for potential advisors, please email me directly.
GenEx: Generating an Explorable World
Taiming Lu ,
Tianmin Shu ,
Junfei Xiao ,
Luoxin Ye ,
Jiahao Wang ,
Cheng Peng ,
Chen Wei ,
Daniel Khashabi ,
Rama Chellappa ,
Alan Yuille ,
Jieneng Chen
Technical report , 2024
arXiv /
genex.world /
(demos)
De-Diffusion Makes Text a Strong Cross-Modal Interface
Chen Wei ,
Chenxi Liu ,
Siyuan Qiao ,
Zhishuai Zhang ,
Alan Yuille ,
Jiahui Yu
CVPR , 2024
arXiv /
project page
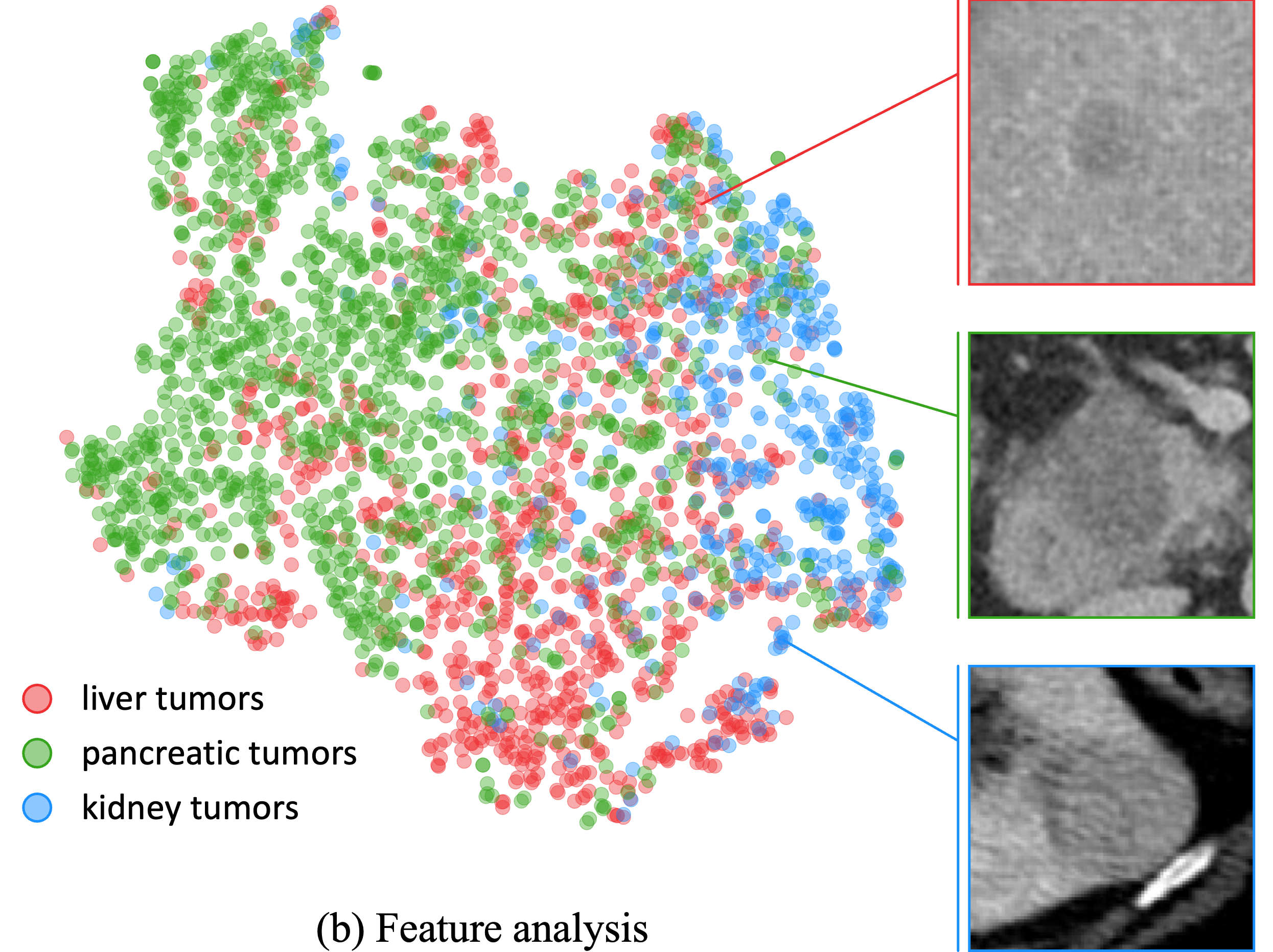
Towards Generalizable Tumor Synthesis
Qi Chen ,
Xiaoxi Chen ,
Haorui Song ,
Alan Yuille ,
Zhiwei Xiong ,
Chen Wei ,
Zongwei Zhou
CVPR , 2024
arXiv /
code
Unleashing the Power of Visual Prompting at the Pixel Level
Junyang Wu* ,
Xianhang Li* ,
Chen Wei ,
Huiyu Wang ,
Alan Yuille ,
Yuyin Zhou ,
Cihang Xie ,
TMLR , 2024
arXiv /
code
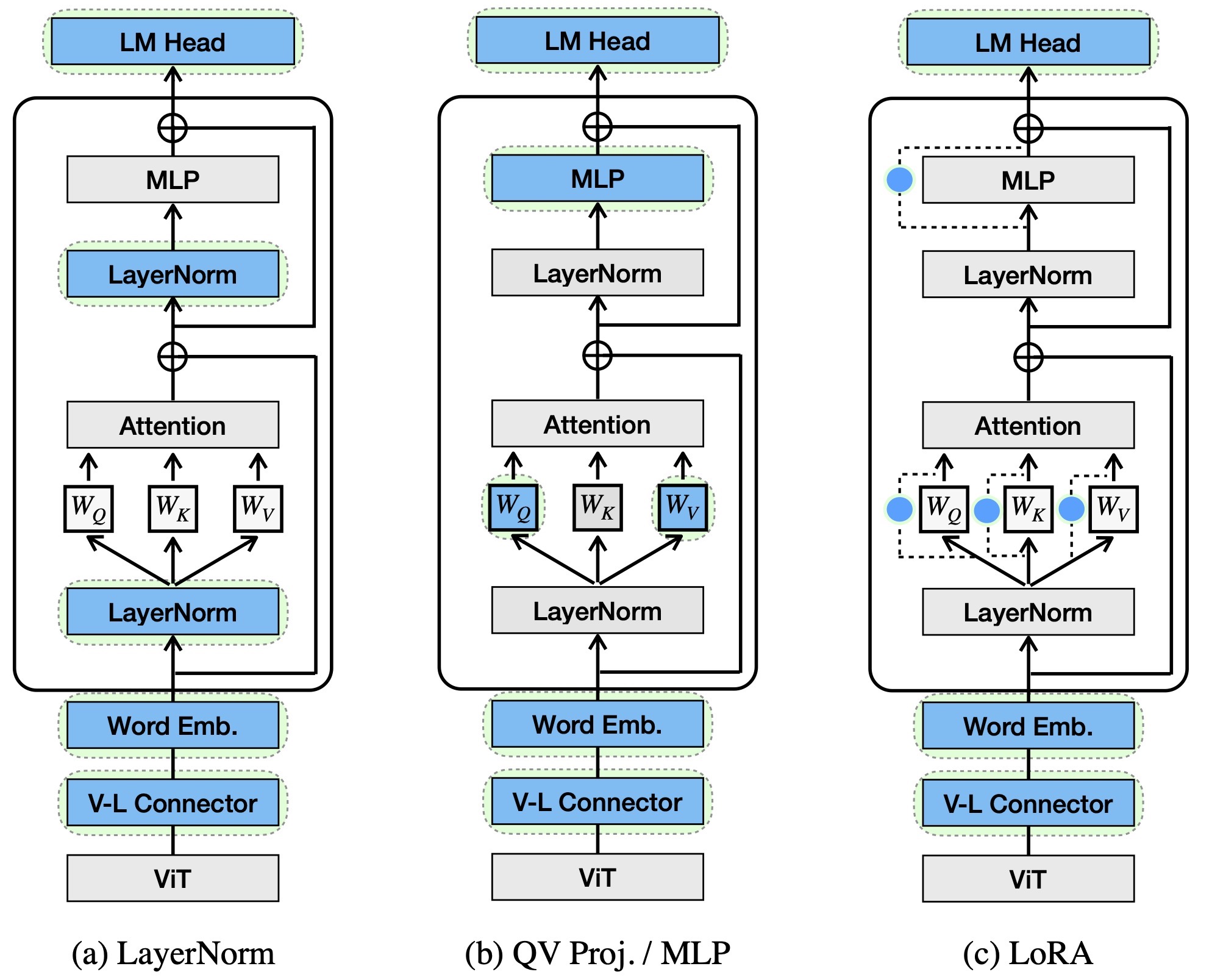
Tuning LayerNorm in Attention: Towards Efficient MultiModal LLM Finetuning
Bingchen Zhao* ,
Haoqin Tu* ,
Chen Wei ,
Jieru Mei ,
Cihang Xie ,
ICLR , 2024 Spotlight
arXiv /
huggingface
Instruct2Attack: Language-Guided Semantic Adversarial Attacks
Jiang Liu ,
Chen Wei ,
Yuxiang Guo ,
Heng Yu ,
Alan Yuille ,
Soheil Feizi ,
Chun Pong Lau ,
Rama Chellappa
arXiv , 2023
arXiv
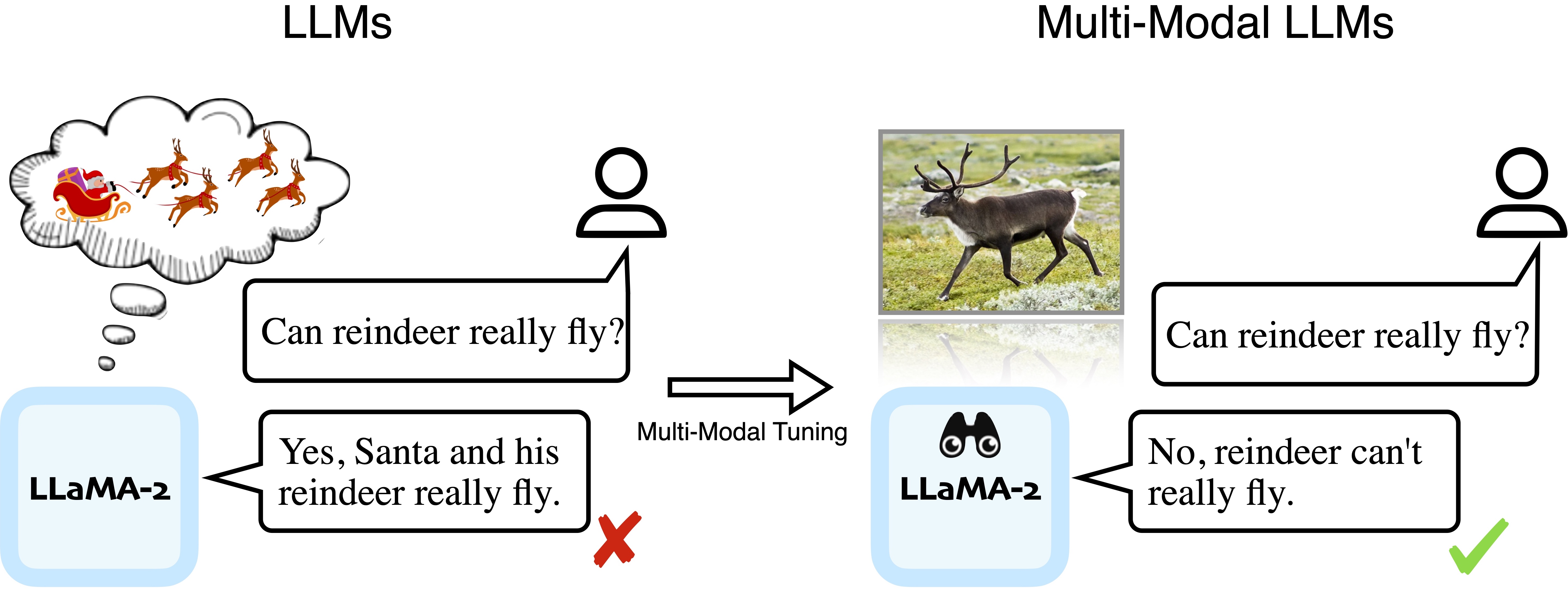
Sight Beyond Text: Multi-Modal Training Enhances LLMs in Truthfulness and Ethics
Haoqin Tu* ,
Bingchen Zhao* ,
Chen Wei ,
Cihang Xie ,
NeurIPS Instruction Workshop , 2023
arXiv /
code
Diffusion Models as Masked Autoencoders
Chen Wei ,
Karttikeya Mangalam ,
Po-Yao Huang ,
Yanghao Li ,
Haoqi Fan ,
Hu Xu ,
Huiyu Wang ,
Cihang Xie ,
Alan Yuille ,
Christoph Feichtenhofer
ICCV , 2023
arXiv /
project page /
Marktechpost
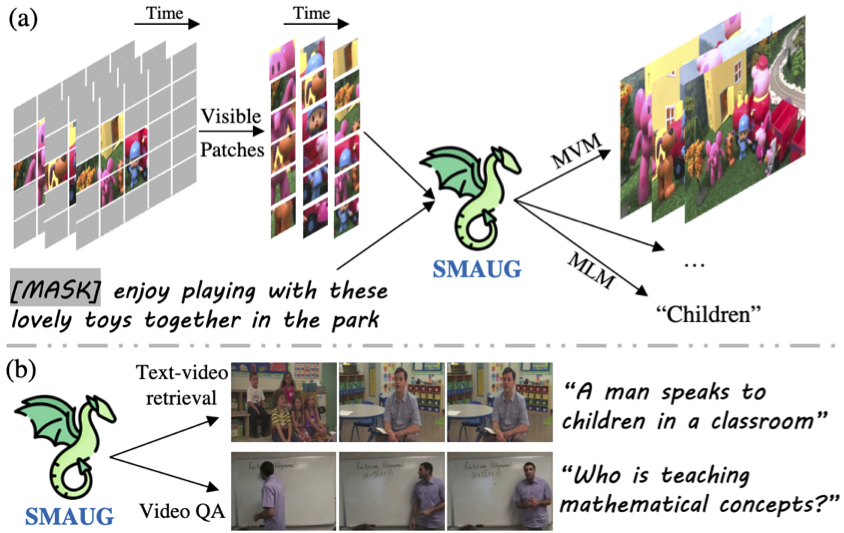
SMAUG: Sparse Masked Autoencoder for Efficient Video-Language Pre-Training
Yuanze Lin ,
Chen Wei ,
Huiyu Wang ,
Alan Yuille ,
Cihang Xie
ICCV , 2023
arXiv
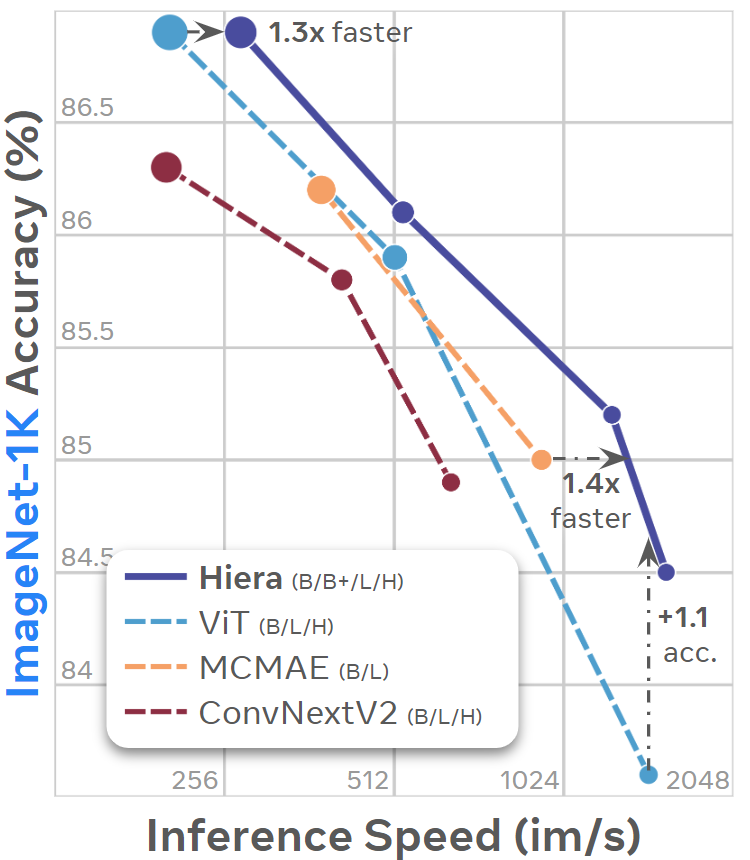
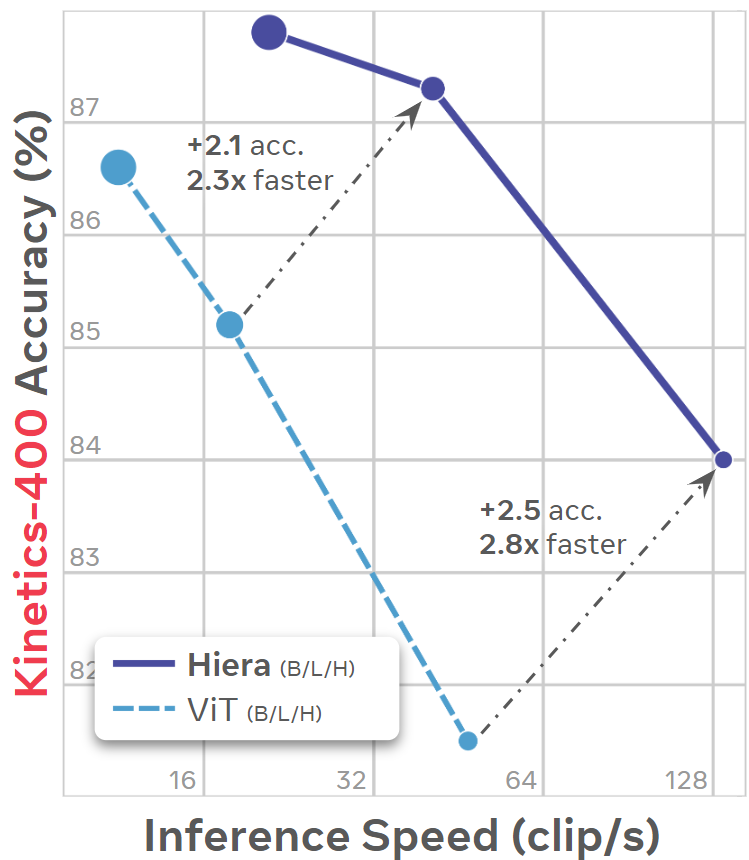
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Chaitanya Ryali *,
Yuan-Ting Hu *,
Daniel Bolya *,
Chen Wei ,
Haoqi Fan ,
Po-Yao Huang ,
Vaibhav Aggarwal ,
Arkabandhu Chowdhury ,
Omid Poursaeed ,
Judy Hoffman ,
Jitendra Malik ,
Yanghao Li *,
Christoph Feichtenhofer *
ICML , 2023 Oral
arXiv /
code
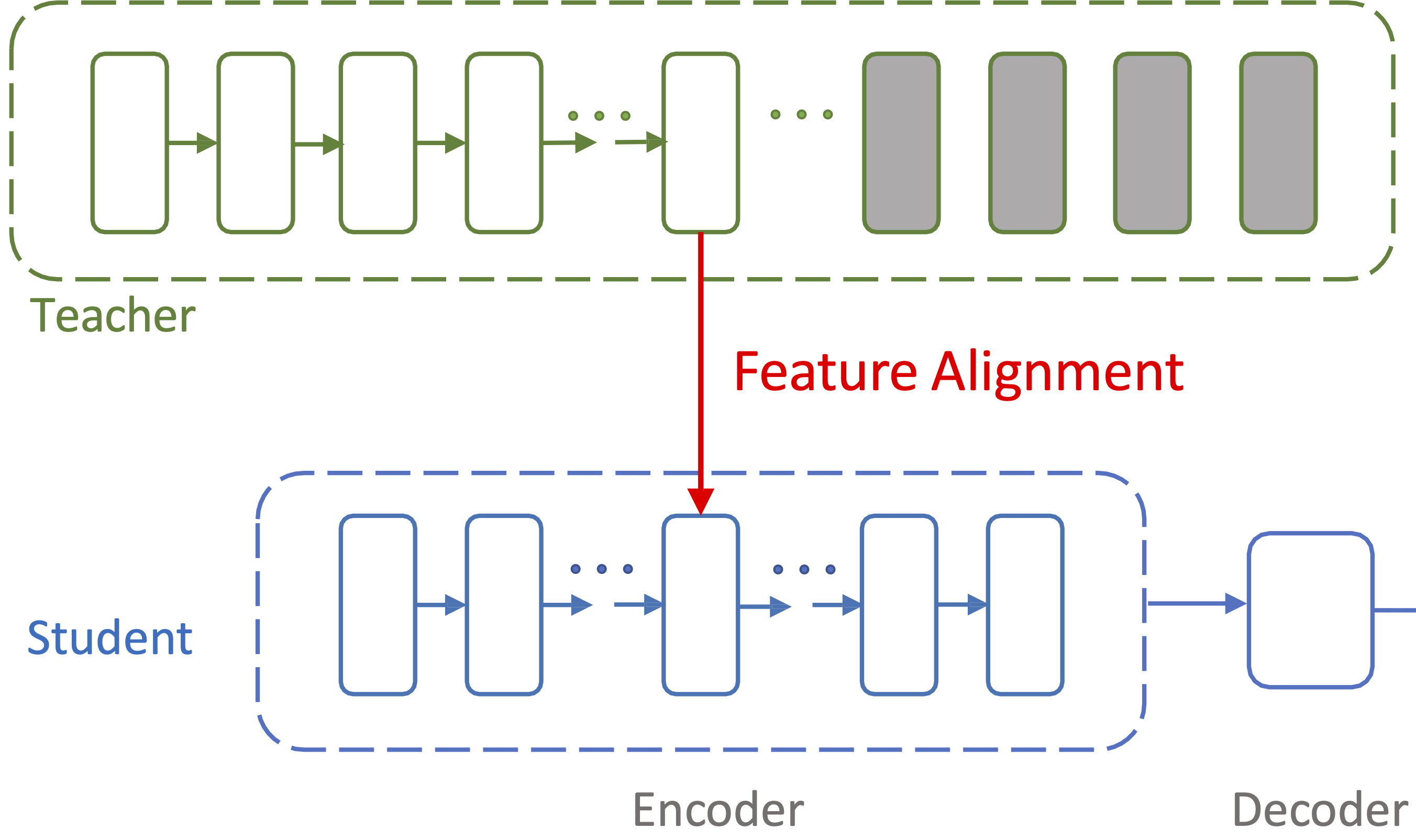
Masked Autoencoders Enable Efficient Knowledge Distillers
Yutong Bai ,
Zeyu Wang ,
Junfei Xiao ,
Chen Wei ,
Huiyu Wang ,
Alan Yuille ,
Yuyin Zhou ,
Cihang Xie
CVPR , 2023
arXiv /
code
CP2: Copy-Paste Contrastive Pretraining for Semantic Segmentation
Feng Wang ,
Huiyu Wang ,
Chen Wei ,
Alan Yuille ,
Wei Shen
ECCV , 2022
arXiv /
code
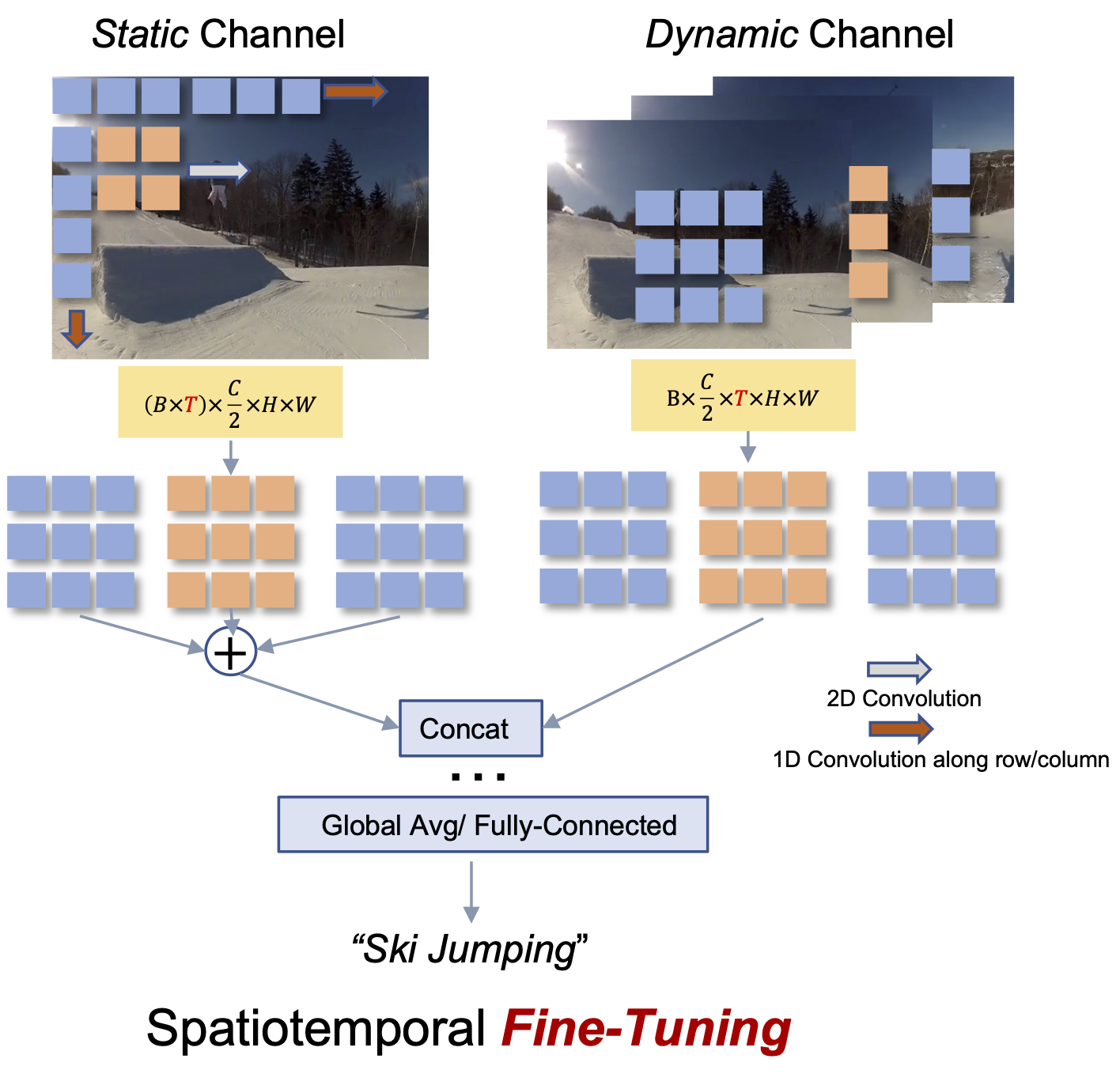
In Defense of Image Pre-Training for Spatiotemporal Recognition
Xianhang Li ,
Huiyu Wang ,
Chen Wei ,
Jieru Mei ,
Alan Yuille ,
Yuyin Zhou ,
Cihang Xie
ECCV , 2022
arXiv /
code
Masked Feature Prediction for Self-Supervised Visual Pre-Training
Chen Wei* ,
Haoqi Fan ,
Saining Xie ,
Chao-Yuan Wu ,
Alan Yuille ,
Christoph Feichtenhofer*
CVPR , 2022
arXiv /
code at pySlowFast
Most Influential CVPR 2023 Papers
iBOT: Image BERT Pre-Training with Online Tokenizer
Jinghao Zhou ,
Chen Wei ,
Huiyu Wang ,
Wei Shen ,
Cihang Xie ,
Alan Yuille ,
Tao Kong
ICLR , 2022
arXiv /
code /
press
Improved and scaled up to the foundation model DINOv2 by Meta AI.
CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
Chen Wei ,
Kihyuk Sohn ,
Clayton Mellina ,
Alan Yuille ,
Fan Yang
CVPR , 2021
arXiv /
code /
poster /
video
CO2: Consistent Contrast for Unsupervised Visual Representation Learning
Chen Wei ,
Huiyu Wang ,
Wei Shen ,
Alan Yuille
ICLR , 2021
arXiv /
Open Review /
video
Iterative Reorganization with Weak Spatial Constraints: Solving Arbitrary Jigsaw Puzzles for Unsupervised Representation Learning
Chen Wei ,
Lingxi Xie ,
Xutong Ren ,
Yingda Xia ,
Chi Su ,
Jiaying Liu ,
Qi Tian ,
Alan Yuille
CVPR , 2019
arXiv /
code
Deep Retinex Decomposition for Low-Light Enhancement
Chen Wei* ,
Wenjing Wang *,
Wenhan Yang ,
Jiaying Liu
BMVC , 2018 Oral
arXiv /
code /
project page & dataset
#2 Most Cited BMVC Papers Over the Last Five Years
GLADNet: Low-Light Enhancement Network with Global Awareness
Wenjing Wang *,
Chen Wei* ,
Wenhan Yang ,
Jiaying Liu
FG Workshop , 2018
PDF /
code /
project page
Research Experience
Postdoc, Meta FAIR, 2024 - 2025
Research Assistant, Johns Hopkins University, CCVL Lab , 2019 - 2024
Student Researcher, Google DeepMind, Summer 2023
Research Intern, Meta FAIR, Summer 2022
Research Intern, Meta FAIR, Summer 2021
Research Intern, Google Cloud AI, Summer 2020
Research Intern, Johns Hopkins University, CCVL Lab , Summer 2018
Engineering Practium Intern, Google, Summer 2017
Research Intern, Peking University, STRUCT Lab , 2017 - 2019